Example COCPs#
Inverted Pendulum#
The inverted pendulum is a classic problem in control theory and robotics that demonstrates the challenge of stabilizing a dynamic system that is inherently unstable. The objective is to keep a pendulum balanced in the upright position by applying a control force, typically at its base. This setup is analogous to balancing a broomstick on your finger: any deviation from the vertical position will cause the system to tip over unless you actively counteract it with appropriate control actions.
We typically assume that the pendulum is mounted on a cart or movable base, which can move horizontally. The system’s state is then characterized by four variables:
Cart position: \( x(t) \) — the horizontal position of the base.
Cart velocity: \( \dot{x}(t) \) — the speed of the cart.
Pendulum angle: \( \theta(t) \) — the angle between the pendulum and the vertical upright position.
Angular velocity: \( \dot{\theta}(t) \) — the rate at which the pendulum’s angle is changing.
This setup is more complex because the controller must deal with interactions between two different types of motion: linear (the cart) and rotational (the pendulum). This system is said to be “underactuated” because the number of control inputs (one) is less than the number of state variables (four). This makes the problem more challenging and interesting from a control perspective.
We can simplify the problem by assuming that the base of the pendulum is fixed. This is akin to having the bottom of the stick attached to a fixed pivot on a table. You can’t move the base anymore; you can only apply small nudges at the pivot point to keep the stick balanced upright. In this case, you’re only focusing on adjusting the stick’s tilt without worrying about moving the base. This reduces the problem to stabilizing the pendulum’s upright orientation using only the rotational dynamics. The system’s state can now be described by just two variables:
Pendulum angle: \( \theta(t) \) — the angle of the pendulum from the upright vertical position.
Angular velocity: \( \dot{\theta}(t) \) — the rate at which the pendulum’s angle is changing.
The evolution of these two varibles is governed by the following ordinary differential equation:
where:
\(m\) is the mass of the pendulum
\(g\) is the acceleration due to gravity
\(l\) is the length of the pendulum
\(\gamma\) is the coefficient of rotational friction
\(J_t = J + ml^2\) is the total moment of inertia, with \(J\) being the pendulum’s moment of inertia about its center of mass
\(u(t)\) is the control force applied at the base
\(y(t) = \theta(t)\) is the measured output (the pendulum’s angle)
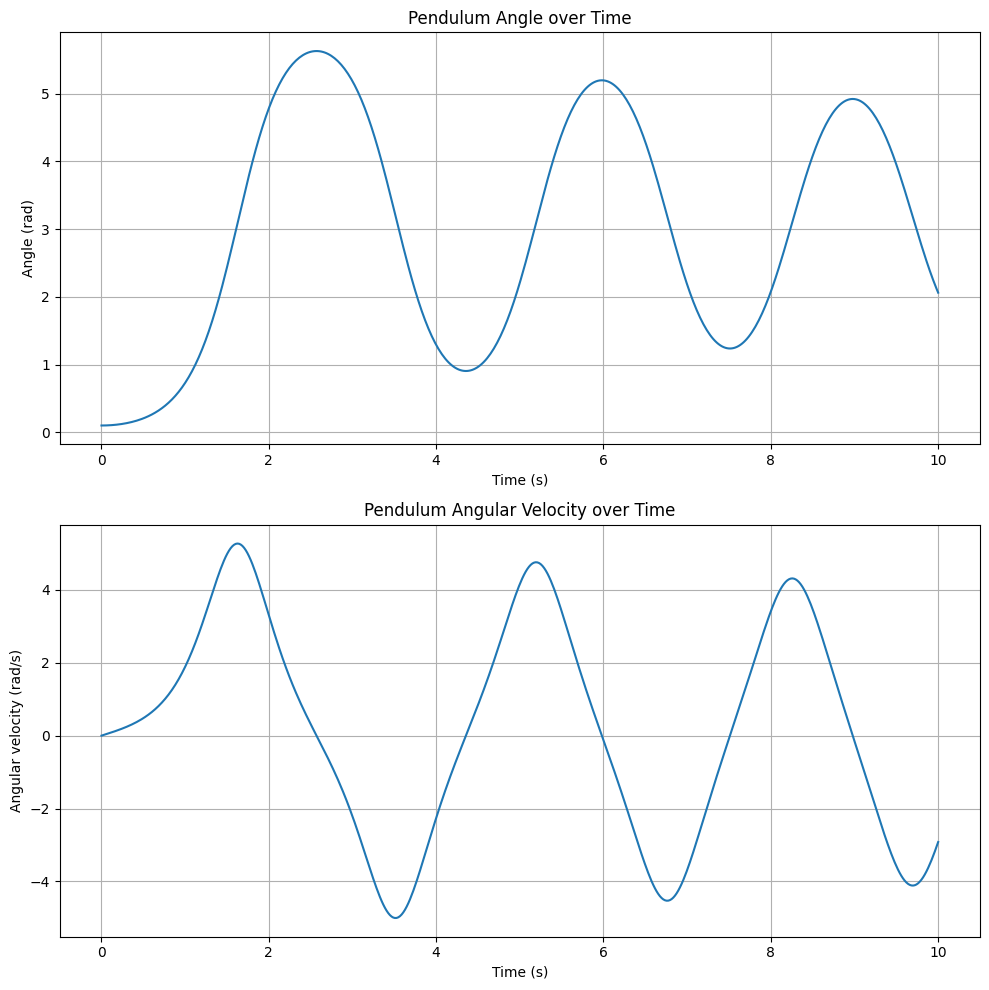
We expect that when no control is applied to the system, the rod should be falling down when started from the upright position.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from scipy.integrate import odeint
from IPython.display import HTML, display
from matplotlib.animation import FuncAnimation
# System parameters
m = 1.0 # mass of the pendulum (kg)
g = 9.81 # acceleration due to gravity (m/s^2)
l = 1.0 # length of the pendulum (m)
gamma = 0.1 # coefficient of rotational friction
J = 1/3 * m * l**2 # moment of inertia of a rod about its center of mass
J_t = J + m * l**2 # total moment of inertia
# Define the ODE for the inverted pendulum
def pendulum_ode(state, t):
theta, omega = state
dtheta = omega
domega = (m*g*l/J_t) * np.sin(theta) - (gamma/J_t) * omega
return [dtheta, domega]
# Initial conditions: slightly off vertical position
theta0 = 0.1 # initial angle (radians)
omega0 = 0 # initial angular velocity (rad/s)
y0 = [theta0, omega0]
# Time array for integration
t = np.linspace(0, 10, 500) # Reduced number of points
# Solve ODE
solution = odeint(pendulum_ode, y0, t)
# Extract theta and omega from the solution
theta = solution[:, 0]
omega = solution[:, 1]
# Create two separate plots
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 10))
# Plot for angle
ax1.plot(t, theta)
ax1.set_xlabel('Time (s)')
ax1.set_ylabel('Angle (rad)')
ax1.set_title('Pendulum Angle over Time')
ax1.grid(True)
# Plot for angular velocity
ax2.plot(t, omega)
ax2.set_xlabel('Time (s)')
ax2.set_ylabel('Angular velocity (rad/s)')
ax2.set_title('Pendulum Angular Velocity over Time')
ax2.grid(True)
plt.tight_layout()
plt.show()
# Function to create animation frames
def get_pendulum_position(theta):
x = l * np.sin(theta)
y = l * np.cos(theta)
return x, y
# Create animation
fig, ax = plt.subplots(figsize=(8, 8))
line, = ax.plot([], [], 'o-', lw=2)
time_text = ax.text(0.02, 0.95, '', transform=ax.transAxes)
def init():
ax.set_xlim(-1.2*l, 1.2*l)
ax.set_ylim(-1.2*l, 1.2*l) # Adjusted to show full range of motion
ax.set_aspect('equal', adjustable='box')
return line, time_text
def animate(i):
x, y = get_pendulum_position(theta[i])
line.set_data([0, x], [0, y])
time_text.set_text(f'Time: {t[i]:.2f} s')
return line, time_text
anim = FuncAnimation(fig, animate, init_func=init, frames=len(t), interval=40, blit=True)
plt.title('Inverted Pendulum Animation')
ax.grid(True)
# Convert animation to JavaScript
js_anim = anim.to_jshtml()
# Close the figure to prevent it from being displayed
plt.close(fig)
# Display only the JavaScript animation
display(HTML(js_anim))