The Bellman optimality equation , whose contraction property underlies the convergence of value iteration, is a functional equation: an equation where the unknown is an entire function rather than a finite-dimensional vector. When the state space is continuous or very large, we cannot represent the value function exactly on a computer. We must instead work with finite-dimensional approximations. This motivates weighted residual methods (also called minimum residual methods), a general framework for transforming infinite-dimensional problems into tractable finite-dimensional ones Chakraverty et al. (2019)Atkinson & Potra (1987).
A Motivating Example: Optimal Stopping with Continuous States¶
Before developing the general theory, consider a concrete example that illustrates the core challenge. An agent observes a state and must decide whether to stop (receive reward and end the episode) or continue (receive nothing, and the state redraws uniformly on ). With discount factor , the Bellman optimality equation is:
The first term is the immediate payoff from stopping; the second is the discounted expected continuation value. Since the continuation value is a constant (it doesn’t depend on the current state ), the optimal policy has a threshold structure: stop if for some threshold , continue otherwise.
At the threshold, the agent is indifferent: . Computing by integrating :
Substituting and solving gives the exact threshold and value.
Source
# label: fig-optimal-stopping-exact
# caption: The exact value function for the optimal stopping problem.
%config InlineBackend.figure_format = 'retina'
import numpy as np
import matplotlib.pyplot as plt
gamma = 0.9
# Solve for exact threshold
v_bar_exact = (1 - np.sqrt(1 - gamma**2)) / gamma**2
s_star_exact = gamma * v_bar_exact
print(f"Exact solution:")
print(f" Threshold s* = {s_star_exact:.6f}")
print(f" Continuation value v̄ = {v_bar_exact:.6f}")
# The exact value function
def v_exact(s):
return np.where(s >= s_star_exact, s, gamma * v_bar_exact)
# Plot the exact value function
s_grid = np.linspace(0, 1, 200)
plt.figure(figsize=(8, 4))
plt.plot(s_grid, v_exact(s_grid), 'b-', linewidth=2, label='Exact $v^*(s)$')
plt.axvline(s_star_exact, color='r', linestyle='--', label=f'Threshold $s^* = {s_star_exact:.3f}$')
plt.xlabel('State $s$')
plt.ylabel('Value $v^*(s)$')
plt.legend()
plt.title('Optimal Stopping: Exact Value Function')
plt.grid(True, alpha=0.3)
plt.tight_layout()Exact solution:
Threshold s* = 0.626789
Continuation value v̄ = 0.696432
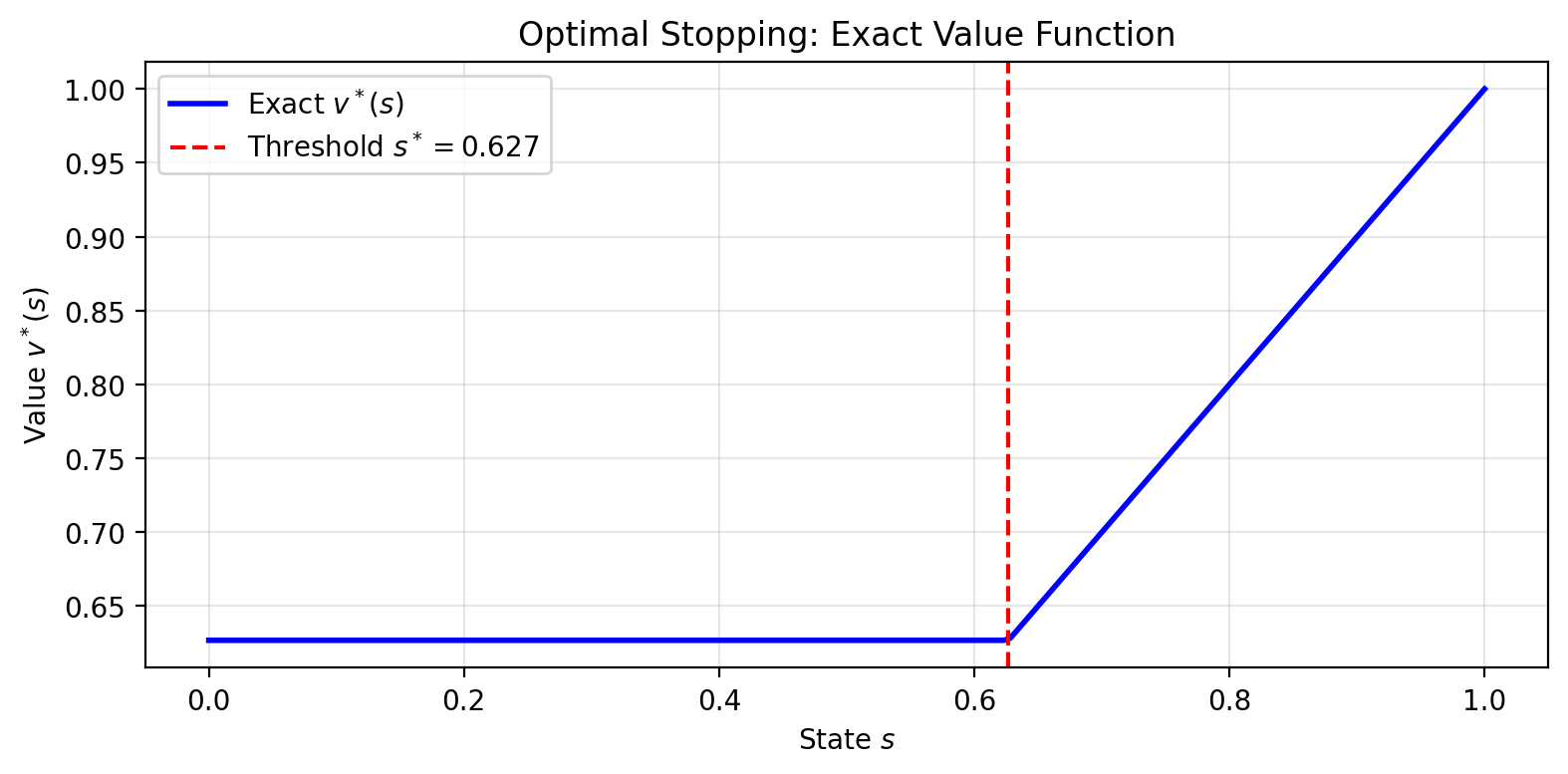
The exact value function is piecewise linear: constant at below the threshold, equal to above it. Now suppose we want to approximate using a polynomial basis with terms:
The residual at state measures how far our approximation is from satisfying the Bellman equation:
For a perfect solution, for all . But a polynomial cannot exactly represent the kink at . We must choose how to make the residual “small” across the state space.
Collocation picks points and requires the residual to vanish exactly there:
Galerkin requires the residual to be orthogonal to each basis function:
Source
# label: fig-collocation-comparison
# caption: Polynomial collocation approximation with 5 Chebyshev nodes.
from scipy.integrate import quad
def chebyshev_nodes(n, a=0, b=1):
"""Chebyshev nodes on [a, b]."""
k = np.arange(1, n + 1)
nodes = 0.5 * (a + b) + 0.5 * (b - a) * np.cos((2*k - 1) * np.pi / (2*n))
return np.sort(nodes)
def collocation_solve(n, gamma, max_iter=100, tol=1e-8):
"""Solve optimal stopping via polynomial collocation."""
nodes = chebyshev_nodes(n)
Phi = np.vander(nodes, n, increasing=True)
theta = np.zeros(n)
for iteration in range(max_iter):
def v_approx(s):
return sum(theta[j] * s**j for j in range(n))
v_bar, _ = quad(v_approx, 0, 1)
targets = np.maximum(nodes, gamma * v_bar)
theta_new = np.linalg.solve(Phi, targets)
if np.linalg.norm(theta_new - theta) < tol:
return theta_new, iteration + 1
theta = theta_new
return theta, max_iter
# Solve with different numbers of basis functions
for n in [3, 5, 8]:
theta, iters = collocation_solve(n, gamma)
def v_approx(s, theta=theta, n=n):
return sum(theta[j] * s**j for j in range(n))
errors = [abs(v_approx(s) - v_exact(s)) for s in np.linspace(0, 1, 1000)]
print(f"n = {n}: converged in {iters} iters, max error = {max(errors):.6f}")
# Plot comparison for n=5
n = 5
theta, _ = collocation_solve(n, gamma)
v_approx_5 = lambda s: sum(theta[j] * s**j for j in range(n))
plt.figure(figsize=(8, 4))
plt.plot(s_grid, v_exact(s_grid), 'b-', linewidth=2, label='Exact')
plt.plot(s_grid, [v_approx_5(s) for s in s_grid], 'r--', linewidth=2, label=f'Collocation ($n={n}$)')
plt.scatter(chebyshev_nodes(n), [v_approx_5(s) for s in chebyshev_nodes(n)],
color='red', s=50, zorder=5, label='Collocation nodes')
plt.xlabel('State $s$')
plt.ylabel('Value')
plt.legend()
plt.title('Polynomial Collocation Approximation')
plt.grid(True, alpha=0.3)
plt.tight_layout()n = 3: converged in 49 iters, max error = 0.053991
n = 5: converged in 41 iters, max error = 0.052626
n = 8: converged in 54 iters, max error = 0.015880
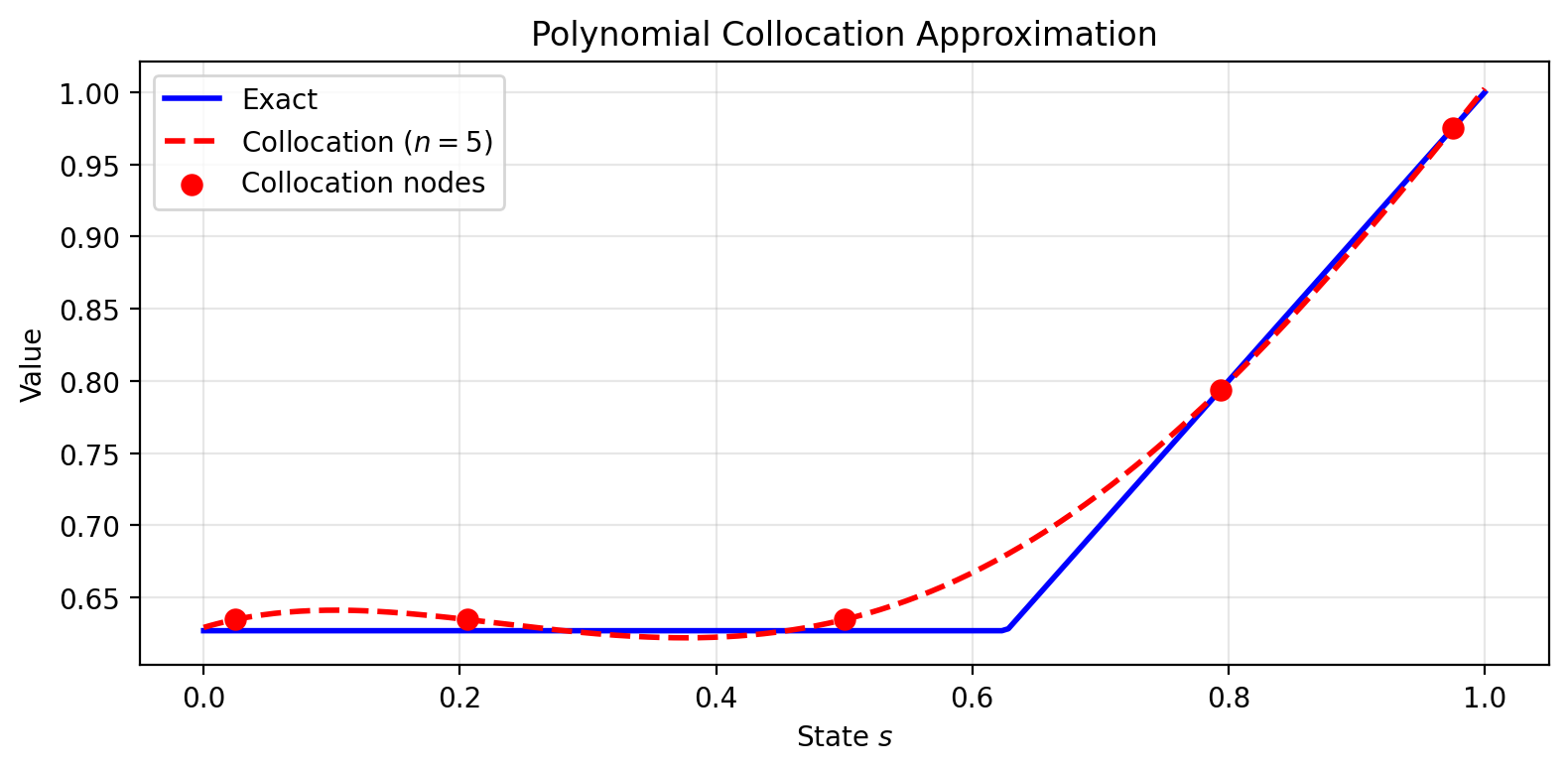
This example illustrates the fundamental tension in weighted residual methods: with finite parameters, we cannot satisfy the Bellman equation everywhere. We must choose how to allocate our approximation capacity. The rest of this chapter develops the general theory behind these choices.
Testing Whether a Residual Vanishes¶
Consider a functional equation , where is an operator and the unknown is an entire function (in our case, the Bellman optimality equation , which we can write as ). Suppose we have found a candidate approximate solution . To verify it satisfies , we compute the residual function . For a true solution, this residual should be the zero function: for every state .
How might we test whether a function is zero? One approach: sample many input points , check whether at each, and summarize the results into a single scalar test by computing a weighted sum with weights . If is zero everywhere, this sum is zero. If is nonzero somewhere, we can choose points and weights to make the sum nonzero. For vectors in finite dimensions, the inner product implements exactly this idea: it tests by weighting and summing. Indeed, a vector equals zero if and only if for every vector . To see why, suppose . Choosing gives , contradicting the claim that all inner products vanish.
The same principle extends to functions. A function equals the zero function if and only if its “inner product” with every “test function” vanishes:
where is a weight function that is part of the inner product definition. Why does this work? For the same reason as in finite dimensions: if is not the zero function, there must be some region where . We can then choose a test function that is nonzero in that same region (for instance, itself), which will produce , witnessing that is nonzero. Conversely, if is the zero function, then for any test function .
This ability to distinguish between different functions using inner products is a fundamental principle from functional analysis. Just as we can test a vector by taking inner products with other vectors, we can test a function by taking inner products with other functions.
Connection to Functional Analysis
The principle that “a function equals zero if and only if it has zero inner product with all test functions” is a consequence of the Hahn-Banach theorem, one of the cornerstones of functional analysis. The theorem guarantees that for any nonzero function in a suitable function space, there exists a continuous linear functional (which can be represented as an inner product with some test function ) that produces a nonzero value when applied to . This is often phrased as “the dual space separates points.”
While you don’t need to know the Hahn-Banach theorem to use weighted residual methods, it provides the rigorous mathematical foundation ensuring that our inner product tests are theoretically sound. The constructive argument we gave above (choosing ) works in simple cases with well-behaved functions, but the Hahn-Banach theorem extends this guarantee to much more general settings.
This transforms the pointwise condition “ for all ” (infinitely many conditions, one per state) into an equivalent condition about inner products. We still cannot test against all possible test functions, since there are infinitely many of those too. But the inner product perspective suggests a natural computational strategy: choose a finite collection of test functions and use them to construct conditions that we can actually compute.
From Variational Conditions to Optimization¶
Making a residual “small” is an optimization problem. We want to find that minimizes for some norm. Different methods correspond to different choices of norm:
Minimize the weighted norm
Minimize a discrete norm at selected points
Minimize in a dual norm induced by the approximation space
The first-order conditions for these optimization problems take the form for appropriate “test functions” . The variational formulation is useful for analysis, but we are simply minimizing the residual in a chosen norm.
The rest of this chapter develops the computational framework: how to parameterize the unknown function, define the residual, choose a norm, and solve the resulting finite-dimensional problem.
The General Framework¶
Consider an operator equation of the form
where is a continuous operator between complete normed vector spaces and . For the Bellman equation, we have , so that solving is equivalent to finding the fixed point .
Just as we transcribed infinite-dimensional continuous optimal control problems into finite-dimensional discrete optimal control problems in earlier chapters, we seek a finite-dimensional approximation to this infinite-dimensional functional equation. Recall that for continuous optimal control, we adopted control parameterization: we represented the control trajectory using a finite set of basis functions (piecewise constants, polynomials, splines) and searched over the finite-dimensional coefficient space instead of the infinite-dimensional function space. For integrals in the objective and constraints, we used numerical quadrature to approximate them with finite sums.
We follow the same strategy here. We parameterize the value function using a finite set of basis functions , commonly polynomials (Chebyshev, Legendre), though other function classes (splines, radial basis functions, neural networks) are possible, and search for coefficients in . When integrals appear in the Bellman operator or projection conditions, we approximate them using numerical quadrature. The projection method approach consists of several conceptual steps that accomplish this transcription.
Step 1: Choose a Finite-Dimensional Approximation Space¶
We begin by selecting a basis and approximating the unknown function as a linear combination:
The choice of basis functions is problem-dependent. Common choices include:
Polynomials: For smooth problems, we might use Chebyshev polynomials or other orthogonal polynomial families
Splines: For problems where we expect the solution to have regions of different smoothness
Radial basis functions: For high-dimensional problems where tensor product methods become intractable
The number of basis functions determines the flexibility of our approximation. In practice, we start with small and increase it until the approximation quality is satisfactory. The only unknowns now are the coefficients .
While the classical presentation of projection methods focuses on polynomial bases, the framework applies equally well to other function classes. Neural networks, for instance, can be viewed through this lens: a neural network with parameters defines a flexible function class, and many training procedures can be interpreted as projection methods with specific choices of test functions or residual norms. The distinction is that classical methods typically use predetermined basis functions with linear coefficients, while neural networks use adaptive nonlinear features. Throughout this chapter, we focus on the classical setting to develop the core concepts, but the principles extend naturally to modern function approximators.
Step 2: Define the Residual Function¶
Since we are approximating with , the operator will generally not vanish exactly. Instead, we obtain a residual function:
This residual measures how far our candidate solution is from satisfying the equation at each point . As we discussed in the introduction, we want to make this residual small—an optimization problem whose formulation depends on how we measure “small.”
Step 3: Minimize the Residual¶
Having chosen our basis and defined the residual, we must find that makes the residual small. This is an optimization problem: we minimize for some norm. The choice of norm determines the method:
| Method | Norm being minimized | Conditions ( equations) |
|---|---|---|
| Least squares | , | |
| Galerkin | (dual norm of approx. space) | , |
| Collocation | (discrete) | , |
The first-order conditions for each optimization problem yield equations in the unknowns . We now describe each method, starting with the most computationally attractive.
Collocation: Make the Residual Zero at Selected Points¶
The simplest approach is to choose points and require the residual to vanish exactly at each:
This gives equations for unknowns. Collocation is computationally attractive because it avoids integration entirely—we only evaluate at discrete points. The resulting system is:
For a linear operator, this is a linear system; for the Bellman equation, it is nonlinear due to the max.
Verify for yourself: with collocation points and basis functions, the system is a linear system. What must be true about the collocation matrix for this system to have a unique solution?
The choice of collocation points matters. Orthogonal collocation (or spectral collocation) places points at the zeros of the -th orthogonal polynomial in a family (Chebyshev, Legendre, etc.). For Chebyshev polynomials , we place collocation points at the zeros of . These points are also optimal nodes for Gauss quadrature, so:
We get the computational simplicity of pointwise evaluation
When we need integrals (inside the Bellman operator), the collocation points double as quadrature nodes with exactness for polynomials up to degree
For smooth problems, spectral approximations achieve exponential convergence: the error decreases like as we add basis functions, compared to for piecewise polynomials
The Chebyshev interpolation theorem guarantees that forcing at these carefully chosen points makes small everywhere, with well-conditioned systems and near-optimal interpolation error.
Galerkin: Make the Residual Orthogonal to the Approximation Space¶
The Galerkin method requires the residual to be orthogonal to each basis function:
To understand why this is optimal, consider the approximation space as an -dimensional subspace. If the residual is orthogonal to all basis functions, then by linearity, is orthogonal to every function in :
The residual has “zero overlap” with our approximation space—it is as “invisible” to our basis as possible. This is the defining property of orthogonal projection.
In what sense is Galerkin minimizing a norm? The dual norm of with respect to measures by its largest inner product with functions in :
The Galerkin conditions for all imply for all , so . Galerkin makes the residual “invisible” when measured against the approximation space—it minimizes the dual norm to zero.
A finite-dimensional analogy: to approximate a vector using only the -plane, the best approximation is . The error points purely in the -direction, orthogonal to the plane. The Galerkin condition generalizes this: the residual is orthogonal to the approximation space.
Galerkin requires integration to compute the conditions, making it more expensive per iteration than collocation. However, when using orthogonal polynomial bases with matching weight functions, the integrals simplify and the resulting systems are well-conditioned.
Least Squares: Minimize the Norm of the Residual¶
The most direct approach is to minimize the weighted norm of the residual:
The first-order conditions are:
This directly minimizes how far our approximation is from satisfying the equation. For the Bellman equation , this is Bellman residual minimization: we minimize .
The gradient involves differentiating the operator . For the Bellman operator with its max, this requires the Envelope Theorem (discussed in Step 4). The need to differentiate through the operator distinguishes least squares from Galerkin and collocation.
Fitted Q-Iteration: Project, Then Iterate¶
For iterative methods, there is a computationally simpler alternative to minimizing the residual directly. Fitted Q-Iteration (FQI) uses a two-step iteration:
Apply the Bellman operator to get a target:
Project the target back onto the approximation space:
The projection step solves , whose first-order conditions are . This is a standard least-squares fit of the basis to the target values. Combining these steps gives:
where denotes orthogonal projection onto with respect to the weighted inner product.
FQI does not minimize the Bellman residual directly. It projects, then iterates. FQI’s projection step uses only the gradient of with respect to (the “semi-gradient”), while Bellman residual minimization requires differentiating through (the “full gradient”). We return to this distinction when discussing temporal difference learning.
Step 4: Solve the Finite-Dimensional Problem¶
The conditions from Step 3 give us a finite-dimensional problem to solve:
Collocation: equations
Galerkin: equations
Least squares: minimize
In each case, we have equations (or first-order conditions) in unknowns . For the Bellman equation, these systems are nonlinear due to the max operator.
Computational Cost and Conditioning¶
The computational cost per iteration varies significantly across methods:
Collocation: Cheapest to evaluate since requires only pointwise evaluation (no integration). The Jacobian is also cheap: .
Galerkin and moments: More expensive due to integration. Computing requires numerical quadrature. Each Jacobian entry requires integrating .
Least squares: Most expensive when done via the objective function, which requires integrating . However, the first-order conditions reduce it to a system like Galerkin, with test functions .
For methods requiring integration, the choice of quadrature rule should match the basis. Gaussian quadrature with nodes at orthogonal polynomial zeros is efficient. When combined with collocation at those same points, the quadrature is exact for polynomials up to a certain degree. This coordination between quadrature and collocation makes orthogonal collocation effective.
The conditioning of the system depends on the choice of test functions. The Jacobian matrix has entries:
When test functions are orthogonal (or nearly so), the Jacobian tends to be well-conditioned. This is why orthogonal polynomial bases are preferred in Galerkin methods: they produce Jacobians with controlled condition numbers. Poorly chosen basis functions or collocation points can lead to nearly singular Jacobians, causing numerical instability. Orthogonal bases and carefully chosen collocation points (like Chebyshev nodes) help maintain good conditioning.
Two Main Solution Approaches¶
We have two fundamentally different ways to solve the projection equations: function iteration (exploiting fixed-point structure) and Newton’s method (exploiting smoothness). The choice depends on whether the original operator equation has contraction properties and how well those properties are preserved by the finite-dimensional approximation.
Method 1: Function Iteration (Successive Approximation)¶
When the operator equation has the form where is a contraction, the most natural approach is to iterate the operator directly:
The infinite-dimensional iteration becomes a finite-dimensional iteration in coefficient space once we choose our weighted residual method. Given a current approximation , how do we find the coefficients for the next iterate ?
Different weighted residual methods answer this differently. For collocation, we proceed in two steps:
Evaluate the operator: At each collocation point , compute what the next iterate should be: . These target values tell us what should equal at the collocation points.
Find matching coefficients: Determine so that for all . This is a linear system: .
In matrix form: , where is the collocation matrix with entries . Solving this system gives .
For Galerkin, the projection condition directly gives a system for . When is linear in its argument (as in many integral equations), this is a linear system. When is nonlinear (as in the Bellman equation), we must solve a nonlinear system at each iteration, though each solution still only involves unknowns rather than an infinite-dimensional function.
When is a contraction in the infinite-dimensional space with constant , iterating it pulls any starting function toward the unique fixed point. The hope is that the finite-dimensional operator, evaluating and projecting back onto the span of the basis functions, inherits this contraction property. When it does, function iteration converges globally from any initial guess, with each iteration reducing the error by a factor of roughly . This is computationally attractive: we only evaluate the operator and solve a linear system (for collocation) or a relatively simple system (for other methods).
However, the finite-dimensional approximation doesn’t always preserve contraction. High-order polynomial bases, in particular, can create oscillations between basis functions that amplify rather than contract errors. Even when contraction is preserved, convergence can be painfully slow when is close to 1, the “weak contraction” regime common in economic problems with patient agents ( or higher). Finally, not all operator equations naturally present themselves as contractions; some require reformulation (like ), and finding a good can be problem-specific.
Method 2: Newton’s Method¶
Alternatively, we can treat the projection equations as a rootfinding problem where for test function methods, or solve the first-order conditions for least squares. Newton’s method uses the update:
where is the Jacobian of at .
To apply this update, we must compute the Jacobian entries . For collocation, , so:
The first term is straightforward (it’s just for a linear approximation). The second term requires differentiating the operator with respect to the parameters.
When involves optimization (as in the Bellman operator ), computing this derivative appears problematic because the max operator is not differentiable. However, the Envelope Theorem resolves this difficulty.
Before reading the box below, try differentiating using the chain rule. What term involving appears? Why might this term vanish at an optimum?
With the Envelope Theorem providing a tractable way to compute Jacobians for problems involving optimization, Newton’s method becomes practical for weighted residual methods applied to Bellman equations and similar problems. The method offers quadratic convergence near the solution. Once in the neighborhood of the true fixed point, Newton’s method typically converges in just a few iterations. Unlike function iteration, it doesn’t rely on the finite-dimensional approximation preserving any contraction property, making it applicable to a broader range of problems, particularly those with high-order polynomial bases or large discount factors where function iteration struggles.
However, Newton’s method demands more from both the algorithm and the user. Each iteration requires computing and solving a full Jacobian system, making the per-iteration cost significantly higher than function iteration. The method is also sensitive to initialization: started far from the solution, Newton’s method may diverge or converge to spurious fixed points that the finite-dimensional problem introduces but the original infinite-dimensional problem lacks. When applying the Envelope Theorem, implementation becomes more complex. We must track the optimal action at each evaluation point and compute the Jacobian entries using the formula above (expected basis function values at next states under optimal actions), though the economic interpretation (tracking how value propagates through optimal decisions) often makes the computation conceptually clearer than explicit derivative calculations would be.
Comparison and Practical Recommendations¶
| Method | Convergence | Per-iteration cost | Initial guess sensitivity |
|---|---|---|---|
| Function iteration | Linear (when contraction holds) | Low | Robust |
| Newton’s method | Quadratic (near solution) | Moderate (Jacobian + solve) | Requires good initial guess |
Which method to use? When the problem has strong contraction (small , well-conditioned bases, shape-preserving approximations like linear interpolation or splines), function iteration is simple and robust. For weak contraction (large , high-order polynomials), a hybrid approach works well: run function iteration for several iterations to enter the basin of attraction, then switch to Newton’s method for rapid final convergence. When the finite-dimensional approximation destroys contraction entirely (common with non-monotone bases), Newton’s method may be necessary from the start, though careful initialization (from a coarser approximation or perturbation methods) is required.
Quasi-Newton methods like BFGS or Broyden offer a middle ground. They approximate the Jacobian using function evaluations only, avoiding explicit derivative computations while maintaining superlinear convergence. This can be useful when computing the exact Jacobian via the Envelope Theorem is expensive or when the approximation quality is acceptable.
Step 5: Verify the Solution¶
Once we have computed a candidate solution , we must verify its quality. Projection methods optimize with respect to specific criteria (specific test functions or collocation points), but we should check that the residual is small everywhere, including directions or points we did not optimize over.
Typical diagnostic checks include:
Computing using a more accurate quadrature rule than was used in the optimization
Evaluating at many points not used in the fitting process
If using Galerkin with the first basis functions, checking orthogonality against higher-order basis functions
In summary, we have established a template: parameterize the unknown function using basis functions, define a residual measuring how far from a solution we are, and impose conditions via inner products with test functions. Different test functions yield different methods: Galerkin uses the basis itself, collocation uses delta functions at chosen points, and least squares uses residual gradients. We now apply this framework to the Bellman equation.
Application to the Bellman Equation¶
Consider the Bellman optimality equation . For a candidate approximation , the residual is:
We examine how collocation and Galerkin, the two most common weighted residual methods for Bellman equations, specialize the general solution approaches from Step 4.
Collocation¶
For collocation, we choose states and require the Bellman equation to hold exactly at these points:
It helps to define the parametric Bellman operator by , the Bellman operator evaluated at collocation point . Let be the matrix with entries . Then the collocation equations become .
Function iteration for collocation proceeds as follows. Given current coefficients , we evaluate the Bellman operator at each collocation point to get target values . We then find new coefficients by solving the linear system . This is parametric value iteration: apply the Bellman operator, fit the result.
When the state space is continuous, we approximate expectations using numerical quadrature (Gauss-Hermite for normal shocks, etc.). The method is simple and robust when the finite-dimensional approximation preserves contraction, but can be slow for large discount factors.
Newton’s method for collocation treats the problem as rootfinding: . The Jacobian is , where the Envelope Theorem (Step 4) gives us . Here is the optimal action at collocation point given the current coefficients.
This converges rapidly near the solution but requires good initialization and more computation per iteration than function iteration. The method is equivalent to policy iteration: each step evaluates the value of the current greedy policy, then improves it.
Why is collocation popular for Bellman equations? Because it avoids integration when testing the residual. We only evaluate the Bellman operator at discrete points. In contrast, Galerkin requires integrating the residual against each basis function.
Worked Example: Collocation on the Optimal Stopping Problem¶
Returning to our motivating example, let us trace through the collocation algorithm with polynomial basis functions at Chebyshev nodes:
Source
import numpy as np
from scipy.integrate import quad
gamma = 0.9
n = 4
# Chebyshev nodes on [0, 1]
k = np.arange(1, n + 1)
nodes = 0.5 + 0.5 * np.cos((2*k - 1) * np.pi / (2*n))
nodes = np.sort(nodes)
# Vandermonde matrix
Phi = np.vander(nodes, n, increasing=True)
# Exact solution
v_bar_exact = (1 - np.sqrt(1 - gamma**2)) / gamma**2
s_star_exact = gamma * v_bar_exact
def v_exact(s):
return np.where(s >= s_star_exact, s, gamma * v_bar_exact)
# Collocation iteration
theta = np.zeros(n)
print("Collocation iteration trace:")
print(f"{'Iter':<6} {'||theta||':<12} {'Max error':<12}")
print("-" * 30)
for iteration in range(15):
def v_approx(s, th=theta):
return sum(th[j] * s**j for j in range(n))
v_bar, _ = quad(v_approx, 0, 1)
test_points = np.linspace(0, 1, 100)
max_error = max(abs(v_approx(s) - v_exact(s)) for s in test_points)
print(f"{iteration:<6} {np.linalg.norm(theta):<12.6f} {max_error:<12.6f}")
targets = np.maximum(nodes, gamma * v_bar)
theta_new = np.linalg.solve(Phi, targets)
if np.linalg.norm(theta_new - theta) < 1e-10:
print(f"\nConverged in {iteration + 1} iterations")
break
theta = theta_newCollocation iteration trace:
Iter ||theta|| Max error
------------------------------
0 0.000000 1.000000
1 1.000000 0.626789
2 1.613062 0.198576
3 0.706118 0.087935
4 1.044850 0.039335
5 1.292433 0.032162
6 1.412062 0.033449
7 1.467070 0.034028
8 1.492030 0.034289
9 1.503301 0.034406
10 1.508381 0.034459
11 1.510668 0.034483
12 1.511698 0.034493
13 1.512161 0.034498
14 1.512370 0.034500
Galerkin¶
For Galerkin, we use the basis functions themselves as test functions. The conditions are:
where is a weight function (often the stationary distribution in RL applications, or simply ). Expanding this:
Function iteration for Galerkin works differently than for collocation. Given , we cannot simply evaluate the Bellman operator and fit. Instead, we must solve an integral equation. At each iteration, we seek satisfying:
The left side is a linear system (the “mass matrix” ), and the right side requires integrating the Bellman operator output against each test function. When the basis functions are orthogonal polynomials with matching weight , the mass matrix is diagonal, simplifying the solve. But we still need numerical integration to evaluate the right side. This makes Galerkin substantially more expensive than collocation per iteration.
Newton’s method for Galerkin similarly requires integration. The residual is , and we need . The Jacobian entry is:
The Envelope Theorem gives , so we must integrate expected basis function values (under optimal actions) against test functions and weight. This requires both numerical integration and careful tracking of optimal actions across the state space, making it substantially more complex than collocation’s pointwise evaluation.
The advantage of Galerkin over collocation lies in its theoretical properties: when using orthogonal polynomials, Galerkin provides optimal approximation in the weighted norm. For smooth problems, this can yield better accuracy per degree of freedom than collocation. In practice, collocation’s computational simplicity usually outweighs Galerkin’s theoretical optimality for Bellman equations, especially in high-dimensional problems where integration becomes prohibitively expensive.
The algorithms above reduce the infinite-dimensional Bellman fixed-point problem to finite-dimensional coefficient computation. Collocation avoids integration entirely by requiring exact satisfaction at discrete points, while Galerkin imposes weighted orthogonality conditions requiring numerical quadrature. Both can be solved via function iteration (when contraction is preserved) or Newton’s method (for faster convergence near the solution). The discrete MDP specialization below reveals connections to algorithms widely used in reinforcement learning.
Exercises: Collocation and Galerkin
Effect of collocation points. For the optimal stopping problem, compare collocation with Chebyshev nodes versus equally-spaced nodes. Which choice gives smaller maximum error?
Threshold location. The optimal stopping policy has a threshold structure. Using your polynomial approximation , estimate the threshold by finding where . Compare to the exact threshold.
Orthogonal polynomials. For , write out the Galerkin conditions using Chebyshev polynomials and weight . What makes this choice computationally convenient?
Newton vs. function iteration. How does the iteration count depend on ? Try .
Galerkin for Discrete MDPs: LSTD and LSPI¶
When the state space is discrete and finite, the Galerkin conditions simplify dramatically. The integrals become sums, and we can write everything in matrix form. This specialization shows the connection to algorithms widely used in reinforcement learning.
For a discrete state space , the Galerkin orthogonality conditions
become weighted sums over states:
where with is a probability distribution over states. Define the feature matrix with entries (each row contains the features for one state), and let be the diagonal matrix with the state distribution on the diagonal.
Policy Evaluation: LSTD¶
For policy evaluation with a fixed policy , the Bellman operator is linear:
With linear function approximation , this becomes:
Let be the vector of rewards , and be the transition matrix with . Then in vector form.
The Galerkin conditions require for all basis functions, which in matrix form is:
Rearranging:
This is the LSTD (Least Squares Temporal Difference) solution. The matrix and vector give the linear system .
When is the stationary distribution of policy (so ), this system has a unique solution, and the projected Bellman operator is a contraction in the weighted norm . This is the theoretical foundation for TD learning with linear function approximation. The fixed point computed here is the same one that TD(0) converges to stochastically; we derive the incremental algorithm in the Monte Carlo chapter.
Check that the dimensions work out: if we have states and basis functions, what are the dimensions of , , , and the matrix ?
Worked Example: LSTD for Policy Evaluation¶
To illustrate LSTD concretely, consider a 3-state Markov chain under a fixed policy:
Source
import numpy as np
P_pi = np.array([[0.7, 0.2, 0.1], [0.3, 0.4, 0.3], [0.1, 0.3, 0.6]])
r_pi = np.array([1.0, 2.0, 0.0])
gamma = 0.9
# Feature matrix: phi_1(s) = 1, phi_2(s) = s
states = np.array([1, 2, 3])
Phi = np.column_stack([np.ones(3), states])
# Uniform weighting
xi = np.ones(3) / 3
Xi = np.diag(xi)
# LSTD matrices
A = Phi.T @ Xi @ (Phi - gamma * P_pi @ Phi)
b = Phi.T @ Xi @ r_pi
theta_lstd = np.linalg.solve(A, b)
v_lstd = Phi @ theta_lstd
v_exact = np.linalg.solve(np.eye(3) - gamma * P_pi, r_pi)
print(f"LSTD solution: theta = ({theta_lstd[0]:.4f}, {theta_lstd[1]:.4f})")
print(f"\n{'State':<8} {'Exact':<12} {'LSTD':<12} {'Error':<12}")
print("-" * 44)
for s in range(3):
print(f"{s+1:<8} {v_exact[s]:<12.4f} {v_lstd[s]:<12.4f} {v_lstd[s] - v_exact[s]:<12.4f}")
# Verify orthogonality
residual = r_pi + gamma * P_pi @ v_lstd - v_lstd
print(f"\nGalerkin orthogonality: <residual, phi_1> = {np.sum(xi * residual * Phi[:,0]):.6f}")LSTD solution: theta = (12.2772, -0.9901)
State Exact LSTD Error
--------------------------------------------
1 10.0207 11.2871 1.2664
2 10.8717 10.2970 -0.5746
3 8.3418 9.3069 0.9652
Galerkin orthogonality: <residual, phi_1> = 0.000000
The Bellman Optimality Equation: Function Iteration and Newton’s Method¶
For the Bellman optimality equation, the max operator introduces nonlinearity:
The Galerkin conditions become:
where the Bellman operator must be evaluated at each state to find the optimal action and compute the target value. This is a system of nonlinear equations in unknowns.
Function iteration applies the Bellman operator and projects back. Given , compute the greedy policy at each state, then solve:
This evaluates the current greedy policy using LSTD, then implicitly improves by computing a new greedy policy at the next iteration. However, convergence can be slow when the finite-dimensional approximation poorly preserves contraction.
Newton’s method treats as a rootfinding problem and uses the Jacobian to accelerate convergence. The Jacobian of is:
To compute , we use the Envelope Theorem from Step 4. At the current , let be the optimal action at state . Then:
Define the policy . The Jacobian becomes:
The Newton update simplifies. We have:
At each state , the greedy value is , which equals . Thus:
The Newton step becomes:
Multiplying through and simplifying:
This is LSPI (Least Squares Policy Iteration). Each Newton step:
Computes the greedy policy
Solves the LSTD equation for this policy to get
Newton’s method for the Galerkin-projected Bellman optimality equation is equivalent to policy iteration in the function approximation setting. Just as Newton’s method for collocation corresponded to policy iteration (Step 4), Newton’s method for discrete Galerkin gives LSPI.
Galerkin projection with linear function approximation reduces policy iteration to a sequence of linear systems, each solvable in closed form. For discrete MDPs, we can compute the matrices and exactly.
Extension to Nonlinear Approximators¶
The weighted residual methods developed so far have focused on linear function classes: polynomial bases, piecewise linear interpolants, and linear combinations of fixed basis functions. Neural networks, kernel methods, and decision trees do not fit this template. How does the framework extend to nonlinear approximators?
Recall the Galerkin approach for linear approximation . The orthogonality conditions for all define a linear system with a closed-form solution. These equations arise from minimizing over the subspace, since at the minimum, the gradient with respect to each coefficient must vanish. The connection between norm minimization and orthogonality holds generally. For any norm induced by an inner product , minimizing with respect to parameters requires . Since , the chain rule gives . Minimizing the residual norm is thus equivalent to requiring orthogonality for all . The equivalence holds for any choice of inner product: weighted integrals for Galerkin, sums over collocation points for collocation, or sampled expectations for neural networks.
For nonlinear function classes parameterized by (neural networks, kernel expansions), the same minimization principle applies:
The first-order stationarity condition yields orthogonality:
The test functions are now the partial derivatives , which span the tangent space to the manifold at the current parameters. In the linear case , the partial derivative recovers the fixed basis functions of Galerkin. For nonlinear parameterizations, the test functions change with , and the orthogonality conditions define a nonlinear system solved by iterative gradient descent.
The dual pairing formulation Legrand & Junca (2025) extends this framework to settings where test objects need not be regular functions. We have been informal about this distinction in our treatment of collocation, but the Dirac deltas used there are not classical functions. They are distributions, defined rigorously only through their action on test functions via . The simple calculus argument for orthogonality does not apply directly to such objects; the dual pairing framework provides the proper mathematical foundation. The induced dual norm measures residuals by their worst-case effect on test functions, a perspective that has inspired adversarial formulations Zang et al. (2020) where both trial and test functions are learned.
The minimum residual framework thus connects classical projection methods to modern function approximation. The unifying principle is orthogonality of residuals to test functions. Linear methods use fixed test functions and admit closed-form solutions. Nonlinear methods use parameter-dependent test functions and require iterative optimization.
We now turn to the question of convergence: when does the iteration converge?
Monotone Projection and the Preservation of Contraction¶
The informal discussion of shape preservation hints at a deeper theoretical question: when does the function iteration method converge? Recall from our discussion of collocation that function iteration proceeds in two steps:
Apply the Bellman operator at collocation points: where
Fit new coefficients to match these targets: , giving
We can reinterpret this iteration in function space rather than coefficient space. Let be the projection operator that takes any function and returns its approximation in . For collocation, is the interpolation operator: is the unique linear combination of basis functions that matches at the collocation points. Then Step 2 can be written as: fit so that for all collocation points, which means .
In other words, function iteration is equivalent to projected value iteration in function space:
We know that standard value iteration converges because is a -contraction in the sup norm. But now we’re iterating with the composed operator instead of alone.
This structure is not specific to collocation. It is inherent in all projection methods. The general pattern is always the same: apply the Bellman operator to get a target function , then project it back onto our approximation space to get . The projection step defines an operator that depends on our choice of test functions:
For collocation, interpolates values at collocation points
For Galerkin, is orthogonal projection with respect to
For least squares, minimizes the weighted residual norm
But regardless of which projection method we use, iteration takes the form .
The central question is whether the composition inherits the contraction property of . If not, the iteration may diverge, oscillate, or converge to a spurious fixed point even though the original problem is well-posed.
Monotone Approximators and Stability¶
The answer turns out to depend on specific properties of the approximation operator . This theory was developed independently across multiple research communities: computational economics Judd (1992)Judd (1996)McGrattan (1997)Santos & Vigo-Aguiar (1998), economic dynamics Stachurski (2009), and reinforcement learning Gordon (1995)Gordon (1999). These communities arrived at essentially the same mathematical conditions.
Monotonicity Implies Nonexpansiveness¶
It turns out that approximation operators satisfying simple structural properties automatically preserve contraction.
This proposition shows that monotonicity and constant preservation automatically imply nonexpansiveness. There is no need to verify this separately. The intuition is that a monotone, constant-preserving operator acts like a weighted average that respects order structure and cannot amplify differences between functions.
Preservation of Contraction¶
Combining nonexpansiveness with the contraction property of the Bellman operator yields the main stability result.
This error bound tells us that the fixed-point error is controlled by how well can represent . If , then and the error vanishes. Otherwise, the error is proportional to the approximation error , amplified by the factor .
Averagers in Discrete-State Problems¶
For discrete-state problems, the monotonicity conditions have a natural interpretation as averaging with nonnegative weights. This characterization was developed by Gordon in the context of reinforcement learning.
Averagers automatically satisfy the monotonicity conditions: linearity follows from matrix multiplication, monotonicity follows from nonnegativity of entries, and constant preservation follows from row sums equaling one.
This specializes the Santos-Vigo-Aguiar theorem to discrete states, expressed in the probabilistic language of stochastic matrices. The stochastic matrix characterization connects to Markov chain theory: represents expected values after one transition, and the monotonicity property reflects the fact that expectations preserve order.
Examples of averagers include state aggregation (averaging values within groups), K-nearest neighbors (averaging over nearest states), kernel smoothing with positive kernels, and multilinear interpolation on grids (barycentric weights are nonnegative and sum to one). Counterexamples include linear least squares regression (projection matrix may have negative entries) and high-order polynomial interpolation (Runge phenomenon produces negative weights).
The following table summarizes which common approximation operators satisfy the monotonicity conditions:
| Method | Monotone? | Notes |
|---|---|---|
| Piecewise linear interpolation | Yes | Always an averager; guaranteed stability |
| Multilinear interpolation (grid) | Yes | Barycentric weights are nonnegative and sum to one |
| Shape-preserving splines (Schumaker) | Yes | Designed to maintain monotonicity |
| State aggregation | Yes | Exact averaging within groups |
| Kernel smoothing (positive kernels) | Yes | If kernel integrates to one |
| High-order polynomial interpolation | No | Oscillations violate monotonicity (Runge phenomenon) |
| Least squares projection (arbitrary basis) | No | Projection matrix may have negative entries |
| Fourier/spectral methods | No | Not monotone-preserving in general |
| Neural networks | No | Highly flexible but no monotonicity guarantees |
The distinction between “safe” (monotone) and “potentially unstable” (non-monotone) approximators provides rigorous foundation for the folk wisdom that linear interpolation is reliable while high-order polynomials can be dangerous for value iteration. But notice that the table’s verdict on “least squares projection” is somewhat abstract. It doesn’t specifically address the three weighted residual methods we introduced at the start of this chapter.
The choice of solution method determines which approximation operators are safe to use. Successive approximation (fixed-point iteration) requires monotone approximators to guarantee convergence. Rootfinding methods like Newton’s method do not require monotonicity. Stability depends on numerical properties of the Jacobian rather than contraction preservation. These considerations suggest hybrid strategies. One approach runs a few iterations with a monotone method to generate an initial guess, then switches to Newton’s method with a smooth approximation for rapid final convergence.
Connecting Back to Collocation, Galerkin, and Least Squares¶
We have now developed a general stability theory for projected value iteration and surveyed which approximation operators are monotone. But what does this mean for the three specific weighted residual methods we introduced at the start of this chapter: collocation, Galerkin, and least squares? Each method defines a different projection operator , and we now need to determine which satisfy the monotonicity conditions that guarantee convergence.
Collocation with piecewise linear interpolation is monotone. When we use collocation with piecewise linear basis functions on a grid, the projection operator performs linear interpolation between grid points. At any state between grid points and , the interpolated value is:
The interpolation weights (barycentric coordinates) are nonnegative and sum to one, making this an averager in Gordon’s sense. Therefore collocation with piecewise linear bases satisfies the monotonicity conditions and the Santos-Vigo-Aguiar stability theorem applies. The folk wisdom that “linear interpolation is safe for value iteration” has rigorous theoretical foundation.
Galerkin projection is generally not monotone. The Galerkin projection operator for a general basis has the form:
where is a diagonal weight matrix and contains the basis function evaluations. This projection matrix typically has negative entries. To see why, consider a simple example with polynomial basis functions on . The projection of a function onto this space involves computing , and the resulting operator can map nonnegative functions to functions with negative values. This is the same phenomenon underlying the Runge phenomenon in high-order polynomial interpolation: the projection weights oscillate in sign.
Since Galerkin projection is not monotone, the sup norm contraction theory does not guarantee convergence of projected value iteration with Galerkin.
Least squares methods share the non-monotonicity issue. The least squares projection operator minimizes and has the same mathematical form as Galerkin projection. It is a linear projection onto with respect to a weighted inner product. Like Galerkin, the projection matrix typically contains negative entries and violates monotonicity.
The monotone approximator framework successfully covers collocation with simple bases, but leaves two important methods, Galerkin and least squares, without convergence guarantees. These methods are used in least-squares temporal difference learning (LSTD) and modern reinforcement learning with linear function approximation. We need a different analytical framework to understand when these non-monotone projections lead to convergent algorithms.
Monotone projections (piecewise linear interpolation, state aggregation) automatically preserve the Bellman operator’s contraction property, guaranteeing convergence of projected value iteration. Non-monotone projections (Galerkin, high-order polynomials) may destroy contraction in the sup norm, requiring either different solution methods (Newton) or analysis in different norms. The next section develops the latter approach for policy evaluation.
Exercises: Monotonicity and Convergence
Verifying monotonicity. Consider piecewise linear interpolation on a 5-point grid. Write out the interpolation weights for a point between grid points 2 and 3. Verify that all weights are nonnegative and sum to one.
A non-monotone example. Using Lagrange interpolation with 4 equally spaced nodes on , compute the interpolation weights for the point . Show that some weights are negative.
State aggregation. Consider a discrete MDP with states aggregated into two groups: and . Write out the aggregation operator as a matrix.
Contraction constant. For the composed operator with a monotone , prove that the contraction constant is exactly .
Beyond Monotone Approximators¶
The monotone approximator theory gives us a clean sufficient condition for convergence: if is monotone (and constant-preserving), then is non-expansive in the sup norm . Since is a -contraction in the sup norm, their composition is also a -contraction in the sup norm, guaranteeing convergence of projected value iteration.
But what if is not monotone? Can we still guarantee convergence? Galerkin and least squares projections typically violate monotonicity, yet they are widely used in practice, particularly in reinforcement learning through least-squares temporal difference learning (LSTD). In general, proving convergence for non-monotone projections is difficult. However, for the special case of policy evaluation, computing the value function of a fixed policy , we can establish convergence by working in a different norm.
The Policy Evaluation Problem and LSTD¶
Consider the policy evaluation problem: given policy , we want to solve the policy Bellman equation , where and are the reward vector and transition matrix under . This is the core computational task in policy iteration, actor-critic algorithms, and temporal difference learning. In reinforcement learning, we typically learn from sampled experience: trajectories generated by following . If the Markov chain induced by is ergodic, the state distribution converges to a stationary distribution satisfying .
This distribution determines which states appear frequently in our data. States visited often contribute more samples and have more influence on any learned approximation. States visited rarely contribute little. For a linear approximation , the least-squares temporal difference (LSTD) algorithm computes coefficients by solving:
where is the matrix of basis function evaluations and . We write this matrix equation for analysis purposes, but the actual algorithm does not compute it this way. For large state spaces, we cannot enumerate all states to form or explicitly represent the transition matrix . Instead, the practical algorithm accumulates sums from sampled transitions , incrementally building the matrices and without ever forming the full objects. The algorithm is derived from first principles through temporal difference learning, and the Galerkin perspective provides an interpretation of what it computes.
LSTD as Projected Bellman Equation¶
To see what this equation means, let be the solution. Expanding the parentheses:
Moving all terms to the left side and factoring out :
Since and the policy Bellman operator is , we can write:
Let denote the -th column of , which contains the evaluations of the -th basis function at all states. The equation above says that for each :
But is exactly the -weighted inner product . So the residual is orthogonal to every basis function, and therefore orthogonal to the entire subspace .
By definition, the orthogonal projection of a vector onto a subspace is the unique vector in that subspace such that is orthogonal to the subspace. Here, lies in (since ), and we have just shown that is orthogonal to . Therefore, , where is orthogonal projection onto with respect to the -weighted inner product:
The weighting by is not arbitrary. Temporal difference learning performs stochastic updates using individual transitions: , with states sampled from . The ODE analysis of this stochastic process (Borkar-Meyn theory) shows convergence to a fixed point, which can be expressed in closed form as the -weighted projected Bellman operator. LSTD is an algorithm that computes this analytical fixed point.
Orthogonal Projection is Non-Expansive¶
Suppose is the steady-state distribution: . Our goal is to establish that is a contraction in . If we can establish that is non-expansive in this norm and that is a -contraction in , then their composition will be a -contraction:
First, we establish that orthogonal projection is non-expansive. For any vector , we can decompose , where is orthogonal to the subspace . By the Pythagorean theorem in the inner product:
Since , we have:
Taking square roots of both sides (which preserves the inequality since both norms are non-negative):
This holds for all , so is non-expansive in .
Contraction of in ¶
To show is a -contraction, we need to verify:
This will be at most if is non-expansive, meaning for any vector . We therefore need to establish that is non-expansive in .
Before reading the proof below, try to show that is non-expansive in . Hint: what property of relates it to ?
Consider the squared norm of . By definition of the weighted norm:
The -th component of is . This is a weighted average of the values with weights that sum to one. Therefore:
Since the function is convex, Jensen’s inequality applied to the probability distribution gives:
Substituting this into the norm expression:
The stationarity condition means for all . Therefore:
Taking square roots, , so is non-expansive in . This makes a -contraction in . Composing with the non-expansive projection:
By Banach’s fixed-point theorem, has a unique fixed point and iterates converge from any initialization.
Interpretation: The On-Policy Condition¶
The result shows that convergence depends on matching the weighting to the operator. We cannot choose an arbitrary weighted norm and expect to be a contraction. Instead, the weighting must have a specific relationship with the transition matrix in the operator : namely, must be the stationary distribution of . This is what makes the weighted geometry compatible with the operator’s structure. When this match holds, Jensen’s inequality gives us non-expansiveness of in the norm, and the composition inherits the contraction property.
In reinforcement learning, this has a practical interpretation. When we learn by following policy and collecting transitions , the states we visit are distributed according to the stationary distribution of . This is on-policy learning. The LSTD algorithm uses data sampled from this distribution, which means the empirical weighting naturally matches the operator structure. Our analysis shows that the iterative algorithm converges to the same fixed point that LSTD computes in closed form.
This is fundamentally different from the monotone approximator theory. There, we required structural properties of itself (monotonicity, constant preservation) to guarantee that preserves the sup-norm contraction property of . Here, we place no such restriction on . Galerkin projection is not monotone. Instead, convergence depends on matching the norm to the operator. When does not match the stationary distribution, as in off-policy learning where data comes from a different behavior policy, the Jensen inequality argument breaks down. The operator need not be non-expansive in , and may fail to contract. This explains divergence phenomena such as Baird’s counterexample Baird (1995).
Exercises: LSTD and the On-Policy Condition
Computing the stationary distribution. For the 3-state Markov chain in the LSTD example, compute the stationary distribution satisfying .
LSTD with stationary weighting. Recompute the LSTD solution using the stationary distribution instead of uniform weighting. Compare the approximation error.
Off-policy divergence. Consider a weighting that does not match the stationary distribution. Implement projected value iteration and observe whether it converges.
Proving non-expansiveness fails off-policy. For , find a vector such that .
The Bellman Optimality Case¶
Can we extend this weighted analysis to the Bellman optimality operator ? The answer is no, at least not with this approach. The obstacle appears at the Jensen inequality step. For policy evaluation, we had:
The inner term is a convex combination of the values , which allowed us to apply Jensen’s inequality to the convex function . For the optimal Bellman operator, we would need to bound:
But the maximum of convex combinations is not itself a convex combination. It is a pointwise maximum. Jensen’s inequality does not apply. We cannot conclude that is non-expansive in any weighted norm.
Is convergence of with Galerkin projection impossible, or merely difficult to prove? The situation is subtle. In practice, fitted Q-iteration and approximate value iteration with neural networks often work well, suggesting that some form of stability exists. But there are also well-documented divergence examples (e.g., Q-learning with linear function approximation can diverge). The theoretical picture remains incomplete. Some results exist for restricted function classes or under strong assumptions on the MDP structure, but no general convergence guarantee like the policy evaluation result is available. The interplay between the max operator, the projection, and the norm geometry is not well understood. This is an active area of research in reinforcement learning theory.
Despite these theoretical gaps, the practical algorithm template is straightforward. We now present fitted-value iteration as a meta-algorithm that combines any supervised learning method with the Bellman operator.
Fitted-Value/Q Iteration (FVI/FQI)¶
We have developed weighted residual methods through abstract functional equations: choose test functions, impose orthogonality conditions , solve for coefficients. What are we actually computing when we solve these equations by successive approximation? The answer is simpler than the formalism suggests: function iteration with a fitting step.
Recall that the weighted residual conditions define a fixed-point problem , where is a projection operator onto . We can solve this by iteration: . Under appropriate conditions (monotonicity of , or matching the weight to the operator for policy evaluation), this converges to a solution.
In parameter space, this iteration becomes a fitting procedure. Consider Galerkin projection with a finite state space of states. Let be the matrix of basis evaluations, the diagonal weight matrix, and the vector of Bellman operator evaluations: . The projection is:
This is weighted least-squares regression: fit to targets . For collocation, we require exact interpolation at chosen collocation points. For continuous state spaces, we approximate the Galerkin integrals using sampled states, reducing to the same finite-dimensional fitting problem. The abstraction remains consistent: function iteration in the abstract becomes generate targets, fit to targets, repeat in the implementation.
This extends beyond linear basis functions. Neural networks, decision trees, and kernel methods all implement variants of this procedure. Given data where , each method produces a function by fitting to the targets. The projection operator is simply one instantiation of a fitting procedure. Galerkin and collocation correspond to specific choices of approximation class and loss function.
The abstraction encapsulates all the complexity of function approximation, whether that involves solving a linear system, running gradient descent, or training an ensemble. Any regression model with a fit(X, y) interface works: LinearRegression, RandomForestRegressor, GradientBoostingRegressor, MLPRegressor, or custom neural networks. The projection operator is one instantiation: when is a linear subspace and we minimize weighted squared error, we recover Galerkin or collocation. The broader view is that FVI reduces dynamic programming to repeated calls to a supervised learning subroutine.
The following code demonstrates fitted-value iteration on the optimal stopping problem:
Source
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
gamma = 0.9
v_bar_exact = (1 - np.sqrt(1 - gamma**2)) / gamma**2
s_star_exact = gamma * v_bar_exact
def v_exact(s):
return np.where(s >= s_star_exact, s, gamma * v_bar_exact)
def fitted_value_iteration(s_grid, gamma, degree, max_iter=50, tol=1e-6):
X = s_grid.reshape(-1, 1)
v = np.zeros(len(s_grid))
for k in range(max_iter):
# Use trapezoidal rule for E[v] under uniform distribution on [0,1]
v_bar = np.trapezoid(v, s_grid)
targets = np.maximum(s_grid, gamma * v_bar)
model = make_pipeline(PolynomialFeatures(degree), Ridge(alpha=1e-6))
model.fit(X, targets)
v_new = model.predict(X)
if np.linalg.norm(v_new - v) < tol:
return v_new, k + 1
v = v_new
return v, max_iter
s_grid = np.linspace(0, 1, 50)
print(f"{'Degree':<10} {'Iterations':<12} {'Max Error':<12}")
print("-" * 34)
for deg in [3, 5, 8]:
v, iters = fitted_value_iteration(s_grid, gamma, deg)
max_error = np.max(np.abs(v - v_exact(s_grid)))
print(f"{deg:<10} {iters:<12} {max_error:<12.6f}")Degree Iterations Max Error
----------------------------------
3 26 0.035112
5 25 0.022469
8 25 0.020715
A limitation of FVI/FQI is that it assumes we can evaluate the Bellman operator exactly. Computing requires knowing transition probabilities and summing over all next states. In practice, we often have only a simulator or observed data. The next chapter shows how to approximate these expectations from samples, connecting the fitted-value iteration framework to simulation-based methods.
Summary¶
This chapter developed weighted residual methods for solving functional equations like the Bellman equation. We approximate the value function using a finite basis, then impose conditions that make the residual orthogonal to chosen test functions. Different choices of test functions yield different methods: Galerkin tests against the basis itself, collocation tests at specific points, and least squares minimizes the residual norm. All reduce to the same computational pattern: generate Bellman targets, fit a function approximator, repeat.
Convergence depends on how the projection interacts with the Bellman operator. The contraction property of the Bellman operator reappears here: whether projected iteration converges depends on whether the projection preserves this contraction or whether we work in a norm compatible with the operator. For monotone projections (piecewise linear interpolation, state aggregation), the composition inherits the contraction property in the sup norm and iteration converges. For non-monotone projections like Galerkin, convergence requires matching the weighting to the stationary distribution, which holds in on-policy settings. The Bellman optimality case remains theoretically incomplete.
Throughout this chapter, we assumed access to the transition model: computing requires summing over all next states weighted by transition probabilities. In practice, we often have only a simulator or observed trajectories, not an explicit model. The next chapter addresses this gap. Monte Carlo methods estimate expectations from sampled transitions, replacing exact Bellman operator evaluations with sample averages. This connects the projection framework developed here to the simulation-based algorithms used in reinforcement learning.
- Chakraverty, S., Mahato, N. R., Karunakar, P., & Rao, T. D. (2019). Weighted Residual Methods. In Advanced Numerical and Semi-Analytical Methods for Differential Equations (pp. 25–44). John Wiley & Sons, Inc. 10.1002/9781119423461.ch3
- Atkinson, K. E., & Potra, F. A. (1987). Projection and Iterated Projection Methods for Nonlinear Integral Equations. SIAM Journal on Numerical Analysis, 24(6), 1352–1373. 10.1137/0724087
- Legrand, M., & Junca, S. (2025). Weighted Residual Solution Methods.
- Zang, Y., Bao, G., Ye, X., & Zhou, H. (2020). Weak adversarial networks for high-dimensional partial differential equations. Journal of Computational Physics, 411, 109409. 10.1016/j.jcp.2020.109409
- Judd, K. L. (1992). Projection methods for solving aggregate growth models. Journal of Economic Theory, 58(2), 410–452.
- Judd, K. L. (1996). Approximation, perturbation, and projection methods in economic analysis. In H. M. Amman, D. A. Kendrick, & J. Rust (Eds.), Handbook of Computational Economics (Vol. 1, pp. 509–585). Elsevier.
- McGrattan, E. R. (1997). Application of Weighted Residual Methods to Dynamic Economic Models.
- Santos, M. S., & Vigo-Aguiar, J. (1998). Analysis of a numerical dynamic programming algorithm applied to economic models. Econometrica, 66(2), 409–426.
- Stachurski, J. (2009). Economic Dynamics: Theory and Computation. MIT Press.
- Gordon, G. J. (1995). Stable function approximation in dynamic programming. Proceedings of the Twelfth International Conference on International Conference on Machine Learning, 261–268.
- Gordon, G. J. (1999). Approximate Solutions to Markov Decision Problems [Phdthesis]. Carnegie Mellon University.
- Baird, L. (1995). Residual algorithms: Reinforcement learning with function approximation. Proceedings of the Twelfth International Conference on Machine Learning, 30–37.